Болотная и Сахарова - 2
01 Feb 2012По мотивам этого
Здорово, что авторы прислушиваются к комментариям. Может и мои когда-нибудь заметят :)
Поэтому, хоть и с запозданием, но оставим тут еще немного брюзжания по теме.
1. Что сравнивали?
В первой статье речь шла о пользователях и ВК, и FB вперемешку (почти 90% из ВК, но все же). В качестве базы для сравнения выбрали только ВК. А из "готовых митинговать" FB-пользователей убрали для чистоты эксперимента?
1.1 Кто попал в "болотников"?
Какие все-таки группы из социальных сетей были выбраны для составления портрета потенциальных митингующих? Хотя бы так - это те, кто записался на мероприятие (а технически - мероприятие - та же группа), или просто участники какой-то организационной группы? Насколько я помню, у основного московского события в ВК к 24 декабря было около 13 тыс. пользователей. Т.е., 20 анализировавшихся в первой части откуда-то еще.
2. Мальчики и девочки
Отличия от "среднего по больнице", действительно, значительны. Для полноты картины возьмем еще и данные Левады по опросу на митинге. М: 60%, Ж: 40%. Что-то среднее между "общевконтактовским" и "болотным". Ближе к "общевконтактному". И тут вот что интересно - как так получается? Девушки не любят афишировать свои планы на ближайшее будущее, или юноши не выполняют свои обещания (в группе отметились, а идти не захотели)? Вопрос для "гендерщиков" :)
3. Возраст
Общая форма кривой в принципе сохраняется, однако, заметна намного большая доля людей младшего возраста и более низкий горб на 21-28.
Простите, но "намного большая доля" и "более низкий горб" - это из серии "мы стали более лучше одеваться". Судя по графику, разница для отдельных категорий составляет где-то 1-2%. Мне такие различия зачимыми не кажутся. Но для того, чтобы не казалось, существует довольно развитый аппарат мат. статистики. Лезем за любезно предоставленными "исходниками в виде таблички, для фанатов" в конце страницы и видим там вместо исходников линейные распределения, по которым рисовались графики. Я-то ожидал настоящие исходники - простыню вида "объекты (пользователи) - признаки". Ну да ладно.
Самое интересное, что всевозможные критерии согласия, действительно, не позволяют принять гипотезу о равенстве распределений возрастов в двух исследуемых группах ("болотниках" и "случайных") на сколько-нибудь значимом доверительном интервале. Т.е., возрастные различия существенны.
Несмотря на относительно небольшое различие в средних (1987 г.р. у "болотников" и 1986 г.р. у "случайных"), у возрастных распределений сильно различаются дисперсии: около 29 лет для "болотников" и 68 лет для "случайных". Одна из возможных версий "событий" - пользователи 1982-1992 г.р. - в среднем - более активны в социальных сетях, в то время как пользователи постарше зачастую заводят себе профиль, но практически не проявляют в нем публичной активности. Повторюсь - это просто одно из предполагаемого множества возможных объяснений различий между "средним по больнице" и пользователями, проявившими активность, записавшись в группу митинга.
4. Т.н. "исходники"
Про то, что там совсем не исходники - уже выше написал. Это примерно как видишь красивую, яркую и нарядную коробку конфет - открываешь, а сами конфеты упаковщица забыла положить или кто-то до тебя их съел :(
Вторая претензия - процентовки. По соцдему - все линейки в сумме дают 100%. Судя по заголовку таблиц, предполагается, что проценты эти взяты от общих выборок (15529 и 19692 аккаунта, соответственно), но строки неответивших нет. Т.е., я должен поверить, что все 15 тыс., случайно попавшие в "средневконтактную" выборку, и все изученные "болотники" указали свой год, месяц и день рождения? В комментарии к первой части исследования я уже вспоминал статистику ВК с Хабра о доле тех, кто указывает свои данные. Здесь только картинка - "КДПВ" :)
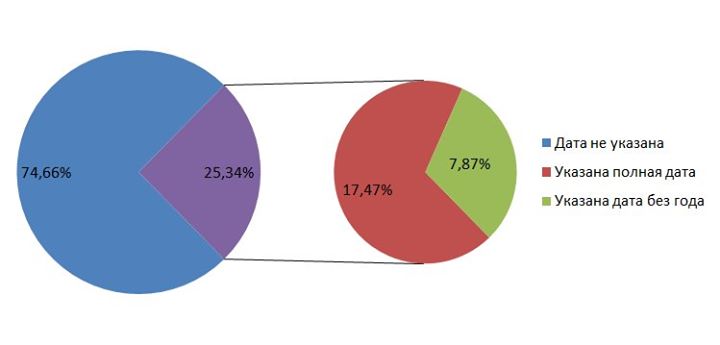
Почему так страшно указать процент "неответивших"? Это же только добавит достоверности и пространства для построения гипотез. Мне, например, интересно, есть ли статистические различия в соотношениях "ответов-неответов" между "среднестатистическими" и "болотниками"?
5. Про группы, фильмы, музыку и прочие маркеры
Просто в качестве пожелания и конструктивного предложения для дальнейшего развития :) Ведь у каждого пользователя может быть много маркеров (членство в разных группах, политика, религия, музыка, фильмы, авторы и т.д.)? Здорово бы было организовать на основе этих данных что-нибудь из серии Market Basket Analysis. Возможно, всплыли бы некие типичные шаблоны и "вкусовые наборы" пользователей. Можно было бы посмотреть соотношение "любителей разных продуктовых наборов" в "болотниках" и "средних". Или вот - например - интересный подход: совмещение Market Basket и Network Analysis. На выходе - сети связанных между собой "покупок" - в нашем случае - указываемых вкусовых предпочтений.
В итоге, из имеющихся данных интересные выводы еще выжимать и выжимать. Так что с нетерпением будем ждать продолжения.